DeepSeek recently released a simple yet effective toolbox for load balancing in Mixture of Experts (MoE) architectures. The EPLB toolbox consists of only one Python file and has already received 1.2k stars on GitHub. The algorithm is heuristic, straightforward, and influential. However, it is described only in the README file—there’s no accompanying paper or technical report. So I spent about an hour reading through its ~160 lines of code and summarized the workflow in this blog.
Background
If you’re unfamiliar with the MoE architecture, the following resources may be helpful:
- Blog by HuggingFace: Mixture of Experts Explained
- Paper by DeepSeek: DeepSeekMoE
- DeepSeek-V3 Technical Report
MoE models activate only a few experts for each input instead of passing the data through the entire network. This allows for scaling up model parameters without significantly increasing computation. In short, an MoE layer includes a router and an expert layer. For each input state, the router assigns an affinity score to each expert. Then, a top-K strategy selects the top K experts to compute the output.
Despite their success, MoE models often suffer from unbalanced expert workloads. This imbalance can lead to router collapse and reduced computational efficiency. To address this, researchers have proposed solutions like:
- Adding auxiliary load-balancing loss when training the router,
- Introducing bias when selecting top-K experts,
- Solving an integer programming problem for load balancing.
EPLB (Expert Parallelism Load Balancer) is DeepSeek’s Python-based tool that helps replicate and allocate experts to GPUs across different nodes. It aims to balance the workload at three levels: nodes, GPUs, and experts.
Algorithm explained
The core idea of EPLB involves two main steps:
- Decomposing the joint decision problem (replication and reallocation) into three smaller subproblems.
- Greedily solving each subproblem.
Here’s how the problem and algorithm are structured.
To aid understanding, the figure below shows an example setup. Each MoE layer includes 16 physical experts (representing 12 logical experts), distributed across 2 computing nodes (each with 4 GPUs). These 16 experts are grouped into 8 sets, which are then assigned to GPUs.

EPLB aims to balance the workload across nodes, groups, and experts by replicating and reallocating experts to GPUs. Because this is a complex joint decision problem, EPLB breaks it into the following subproblems:
- Given current groups, allocate these groups to nodes.
- Objective: balance the workload between nodes.
- Algorithm: Balanced Packing
- In each node, replicate the experts.
- Objective: balance the workload between experts.
- Algorithm: Balanced Replication.
- In each node, allocate experts to groups.
- Objective: balance the workload between groups.
- Algorithm: Balanced Packing
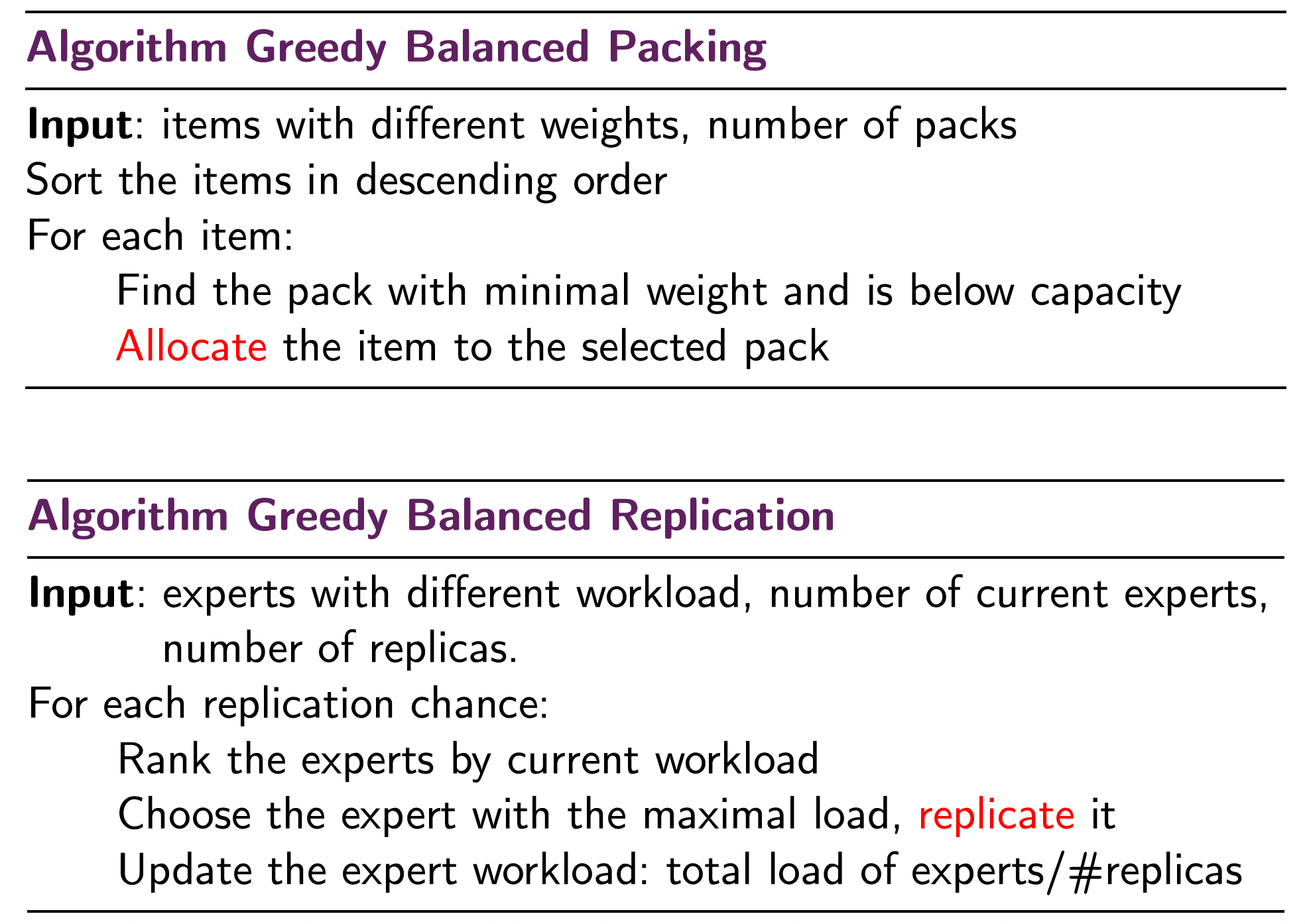
Note that steps 1 and 3 both use the same packing algorithm, while step 2 uses a different replication algorithm. EPLB applies greedy strategies to solve both. Here I summarized the pseudocode used in EPLB:
Heuristic or Optimization?
EPLB relies on a series of heuristics—specifically, hierarchical load balancing and greedy algorithms. Still, the approach is impactful in the AI community. Nowadays, efficient and intuitive algorithms are often preferred, as they are usually good enough for practical use.
In contrast, seeking an optimal solution may require significantly more computational resources and can even lead to “overfitting”—not just in the training/testing sense, but also with respect to the optimization objective itself versus other goals that are not explicitly optimized.
As someone who has worked in optimization, I believe it’s increasingly important to improve computational efficiency for finding the optimal solution and, at times, embrace heuristics :)